

Sketchnotes sind nicht nur online toll, sie machen vor allem offline Spaß. Ich freue mich sehr, dass ich mit spreadshirt eine optimale Platform gefunden habe, damit Ihr Euer Lieblingsmotiv auf T-Shirts, Hoodies, Tassen, Beutel, Taschen oder Caps bringen kann. Es gibt nun auch Postkarten, die ich zu verschiedenen Veranstaltungen mitbringe.
Viele meiner Sketchnotes haben eine Geschichte, die sie besonders machen. Ich möchte Euch hier ein paar dieser Geschichten erzählen.
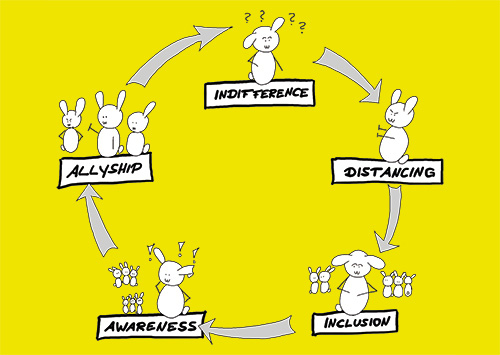
5 (P)Hasen der Allyship
Postkarten | Shirts | Stoffbeutel | weitere…
Menschen, die anderen marginalisierten Menschen zur Seite stehen und sie unterstützen, werden Allies (Verbündete) genannt.
Allyship ist einfach? Nein, ist sie nicht. Denn Allyship ist vor allem ein Findungsprozess, der im Bild sichtbar gemacht wird. Meine eigene Postionierung als weiße Person kann in jedem Augenblick anders aussehen. Nicht ich definiere mich als Verbündete*r, sondern meine Handlungen in Situationen, in denen andere Menschen diskriminiert werden. Wo warst Du, als Du das letzte Mal eine Diskriminierung beobachtet hast?
Falls Du Dich übrigens fragst, wie unser*e Häs*in heisst. Darf ich vorstellen? Das ist Ally.
Update: im Dezember 2023 habe ich Lesbarkeit der Phasen Indifference, Distancing, Inclusion, Awareness und Allyship verbessert.

Es gibt viele Menschen, die bis heute die Auswirkungen dieser Zeit verspüren. Gerade an einem Arbeitsplatz, der im Zielbild von Vertrauen, Offenheit und Sicherheit spricht, hat dieser alte Begriff schlichtweg keinen Platz mehr. Tatsächlich entspricht der Begriff „Mentor“ viel mehr dem Charakter dieser Rolle, denn Scrum Mentor*innen sollten ihren Teams durch Erfahrung, Rat und Tat dabei helfen, ihren Arbeitsplatz frei, individuell und in Sicherheit ausfüllen zu können. Deshalb: Check Your Title, Stop Racism!

Dieses Motiv entstand in einem Workshop zum Thema „Impostor Syndrom“ während der SoCraTes Konferenz 2022 in Soltau.
Der Titel „Senior Impostor“ erkennt an, dass es dieses Syndrom gibt und dass es viele Menschen begleitet und beeinflusst. Das Ummünzen zu einen Jobtitel soll zeigen, dass es Möglichkeiten gibt, mit diesem Syndrom umzugehen. Denn alles, was Dir hilft, Dein Impostor-Syndrom anders zu betrachten, wird Dir auch neue Erkenntnisse bringen.

Oder…? Vielleicht doch nicht? Das Impostor Syndrom kann jede Person treffen. Verschweig‘ es nicht, spricht mit Menschen darüber. Dieses Phänomen betrifft mehr Menschen, als Du vielleicht bisher gedacht hast. Und wer weiß? Vielleicht findest Du mit diesem Shirt genau die für Dich passenden Mentor*innen…
